Urllib3 是一个功能强大,条理清晰,用于HTTP客户端的Python库,许多Python的原生系统已经开始使用urllib3。
文档 https://urllib3.readthedocs.io/en/latest/
Urllib3 提供了很多python标准库里所没有的重要特性:
- 线程安全
- 连接池
- 客户端SSL/TLS验证
- 文件分部编码上传
- 协助处理重复请求和HTTP重定位
- 支持压缩编码
- 支持HTTP和SOCKS代理
- 100% 测试覆盖率
上面这段是抄的,说实话实际用来下我没感觉出和 urllib2、requests 有多大的区别,爬虫的招式都差不多,urllib3 给我的最大的感受是简洁易用,还有可能比 requests 稍微快一点。搜了一下目前也鲜有介绍 urllib3 的中文教程,索性连同爬虫知识一起分享一下吧。
安装
pip install urllib3
基本抓取
1. 基本使用
import urllib3
http = urllib3.PoolManager() # 创建请求
ret = http.request('GET', 'www.baidu.com') # 返回一个 HTTPResponse 对象
print(ret.status) # 返回状态 200/404/...
print(ret.data) # 返回的数据
2. 设置 headers/Cookies/UA
headers = {
"Cookies":"xxxx",
"User-Agent":"xxxx"
}
ret = http.request('GET', url, headers=headers)
3. 处理 warning
urllib3.disable_warnings()
4. 使用代理
proxy = urllib3.ProxyManager('http://127.0.0.1:1080/') # 使用本地的 http 代理
proxy.request('GET', 'http://google.com/')
5. 编码问题
ret.data 返回的数据类型是 byte string,转成字符串需要 decoder,直接用.decode('utf8') 或 .decode("unicode-escape")即可,不同网页的编码是不同的,可能会存在一些问题,因此见下面方法:
5.1 方法一:直接解码输出
print(ret.data.decode('utf-8'))
print(ret.data.decode('utf-8', 'ignore')) # 或'replace' # 解决混入了其他编码 如\x00
print(ret.data.decode('unicode-escape')) # 6个 ascii 字符的情况
5.2 方法二:使用 codecs(推荐)
添加参数preload_content=False 以便后面用 codecs 进行解码,这样可以避免因为 emoji 造成的报错
import codecs
ret = http.request('GET', url, preload_content=False)
reader = codecs.getreader('utf-8') # 设置 codecs 的编码
ret = reader(ret) # 解码
常用技巧整理
1. 抓取 cookies 并使用 cookies 登陆
利用抓包工具 Fiddler
- 打开 Fiddler 即开始抓包 (ctrl + x) 可以清空记录
- 打开网页账户登录页面(默认系统代理,不要开代理)
- 找到跳转之后的第一个页面
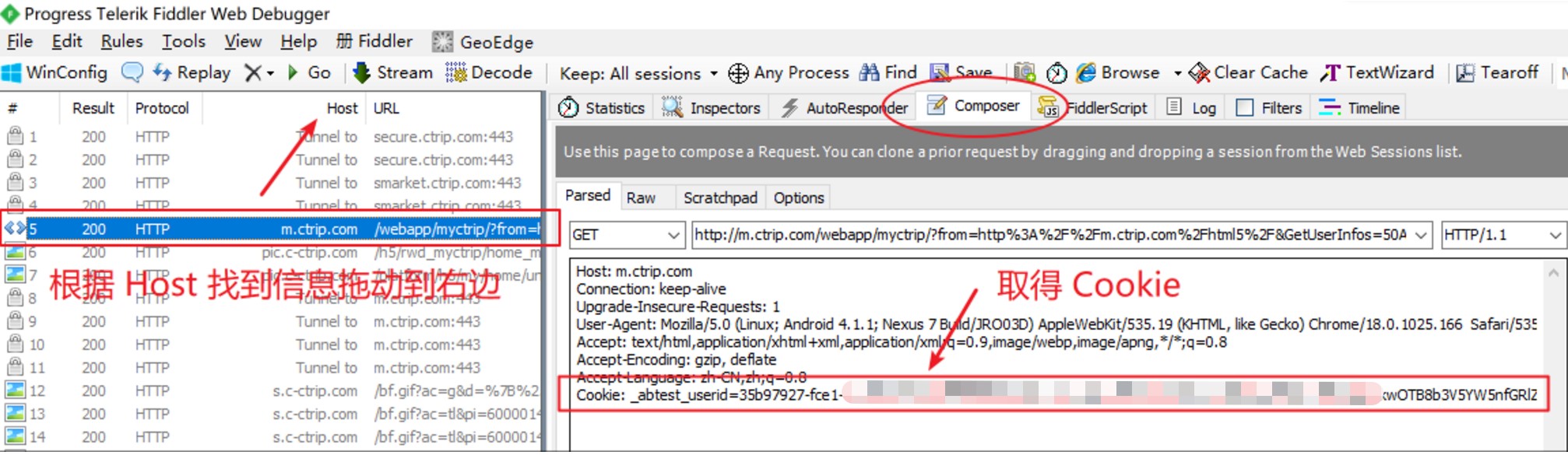
headers = {
'User-agent':'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36',
'Cookie':"xxxxxxx;xxxxxx=xxxxxxxx"
}
http = urllib3.PoolManager()
ret = http.request('GET', url, headers=headers)
2. POST 参数
这类网页需要用户发送一些请求的数据才能得到想要的内容,因此不能用 GET 的方式,需要使用 POST 方式
post_data = { # 需要发送的内容,字典形式
'fake_data':'data',
'fake_id':'000001'
}
url = "http://www.xxxx.com/post"
encoded_args = urlencode(post_data) # 使用 urlencode 进行编码
url_target = url + "?%s" % encoded_args # 正确的 url 格式
http = urllib3.PoolManager()
r = http.request('POST', url_target)
3. 请求 JSON 类型的数据
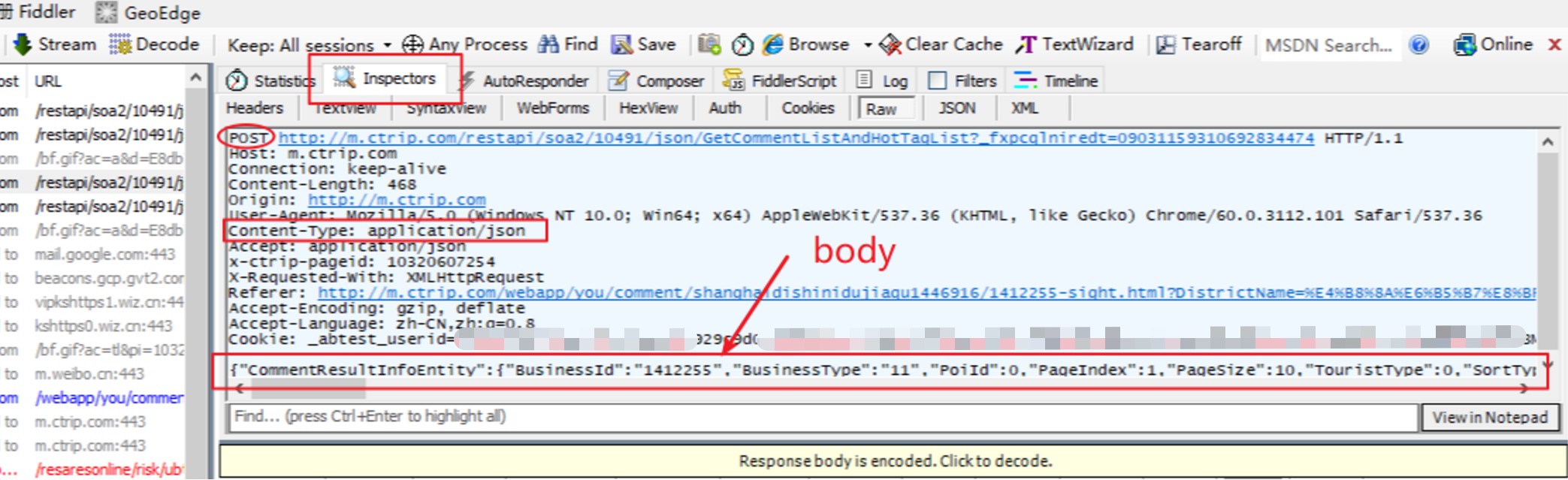
- JSON 方法的页面的最大特征是:直接打开网址会返回“参数错误”
- 请求网页需要 发送 JSON 格式的数据,要与一般的 POST 方法区分开来
- 例如携程的用户评论数据就要用这种方式请求到
- 需要传入
body参数,而且必须是字符串,不是字典
import json
# 方法1
data = {'attribute': 'value'} # 自定义一些字典数据
body_data = json.dumps(data).encode('utf-8')
# 方法2
body_data = '{"xxx": {"xx": "xxx", "xxx":"xxx"}}' # 字符串
r = http.request(
'POST', url,
body=body_data, # 关键:数据要传入 body 参数,不是 fields
headers={'Content-Type': 'application/json'})
4. 表单数据 Form Data
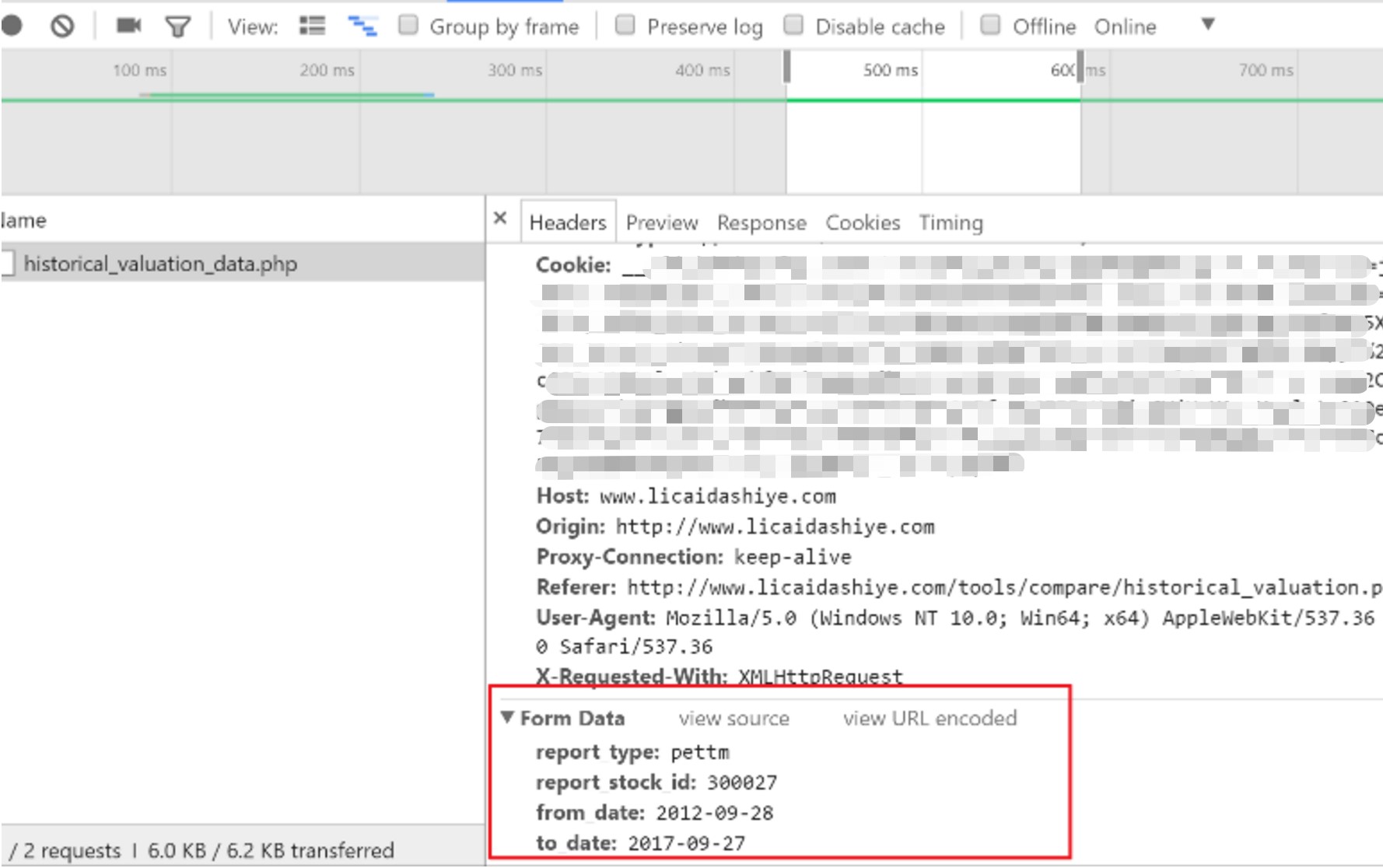
这类网页需要传入一个表单数据,在 urllib3 中传入 fields 参数即可
r = http.request('POST', url, fields={'field': 'value'})
数据处理
关于网页数据处理的利器 beautiful soup、re 的介绍就略啦,这里分享一些其他技巧。
1. 去除 emoji/空格/反斜杠
import re
def del_emoji(string):
pattern1 = re.compile(u'[^\u0000-\uD7FF\uE000-\uFFFF]', re.UNICODE) # Emoji
pattern2 = re.compile('\s*') # 空格
pattern3 = re.compile('\\\\*') # 反斜杠
string = re.sub(pattern1, '', string)
string = re.sub(pattern2, '', string)
string = re.sub(pattern3, '', string)
return string
2. 处理 json 时间戳
有时候得到的时间格式是这样的 '/Date(-62135596800000-0000)/'不要慌,这本质上就是一种时间戳。相关文档看 这里,可以 在线转换。
-62135596800000 表示 GMT: 0001年Jan1日MondayAM12点00分
1504071373 表示 GMT: 2017年Aug30日WednesdayAM5点36分
最后 -0000 表示时区, 例如0800表示 08:00 即北京时间
- 转换方法即取前 10 位,即 timestamp,进行转换
time.strftime("%Y-%m-%d", time.localtime(1504071373))